
From Fragmented Information to Structured Insights
Building a Temporally-Aware Knowledge Graph from European Energy Industry News


1. Introduction
After transitioning from academia (Astrophysics) to the energy industry, I noticed that while academic knowledge often flows through centralized channels (e.g., arXiv), industry news and developments are far more scattered across a constellation of sources, each with its own publication cadence, focus, and depth. This fragmentation is especially pronounced in the European energy sector, where regulatory updates from transmission system operators (TSOs), market analyses from trading platforms, policy directives from governmental bodies, and industry commentary from specialized outlets collectively shape the landscape - yet rarely converge into a unified view.
With this project (GitHub), I aim to address this challenge by developing an automated system that uses Natural Language Processing (NLP) and Large Language Models (LLMs) to transform this fragmented information ecosystem into a coherent, temporally aware knowledge structure. The core idea lies not merely in aggregation but in constructing a dynamic knowledge graph that captures the evolution of entities, relationships, and events over time - enabling both retrospective analysis and forward-looking insights.
The project's ambition extends beyond personal utility. By documenting its development - from web scraping to knowledge graph construction - I want to provide a reproducible framework for similar challenges in other dynamic, information-intensive industries. Focusing on Germany's energy market serves as a proving ground: besides personal interest, it offers ample complexity through its multi-stakeholder environment (four TSOs, federal and European regulators, multiple market platforms) while still maintaining a manageable scope.
2. Data Collection and Processing Pipeline
Source Selection and Coverage
In the initial stage, I focus on 13 key information sources that collectively provide comprehensive coverage of the German and European energy landscape:
Transmission System Operators (TSOs): 50Hertz, TenneT, Amprion, and TransnetBW - the four pillars of Germany's electricity transmission infrastructure, as well as ENTSO-E (European Network of TSOs)
Regulatory Bodies: Bundesnetzagentur (German Federal Network Agency) and ACER (European Agency for the Cooperation of Energy Regulators)
Market Platforms: EEX (European Energy Exchange), and SMARD (German electricity data)
Analysis and Commentary: Clean Energy Wire, ICIS, Agora Energiewende, and the European Commission's energy portal
This source portfolio ensures that I capture technical grid updates, regulatory decisions, market dynamics, and policy discourse-the full spectrum of factors influencing energy markets.
Technical Implementation and Challenges
When I developed the scraping infrastructure - deployed via GitHub Actions for daily automated collection - I encountered a series of technical challenges that showed just how heterogeneous web-based information sources can be.
I chose the Crawl4AI library as my primary scraping tool because it reliably scrapes most of the sources with minimal adjustments and converts raw HTML into clean, structured markdown. Still, several sites resisted a straightforward approach and forced me to engineer more tailored solutions:
TSO Websites (50Hertz, TenneT): Modern JavaScript-heavy interfaces prevented direct crawling. The solution involved a two-phase approach: first extracting article URLs, then individual scraping with depth=1. For 50Hertz, even this proved insufficient, necessitating direct Playwright automation to bypass anti-bot measures.
Bundesnetzagentur: Legacy PHP architecture required manual URL collection and sequential processing, highlighting how governmental sites often lag in web technology adoption.
Clean Energy Wire: Aggressive rate limiting (IP blocks after excessive requests) demanded careful request throttling, so a careful back-off and delay system was developed.
Data Cleaning and Standardization
Raw scraped content, even when converted to markdown, contained substantial noise: navigation links, footer text, cookie notices, and formatting artifacts. Building a cleaning pipeline, I employed source-specific rules to extract article bodies, typically by identifying consistent structural markers (e.g., content boundaries defined by a publication date or markdown patterns).
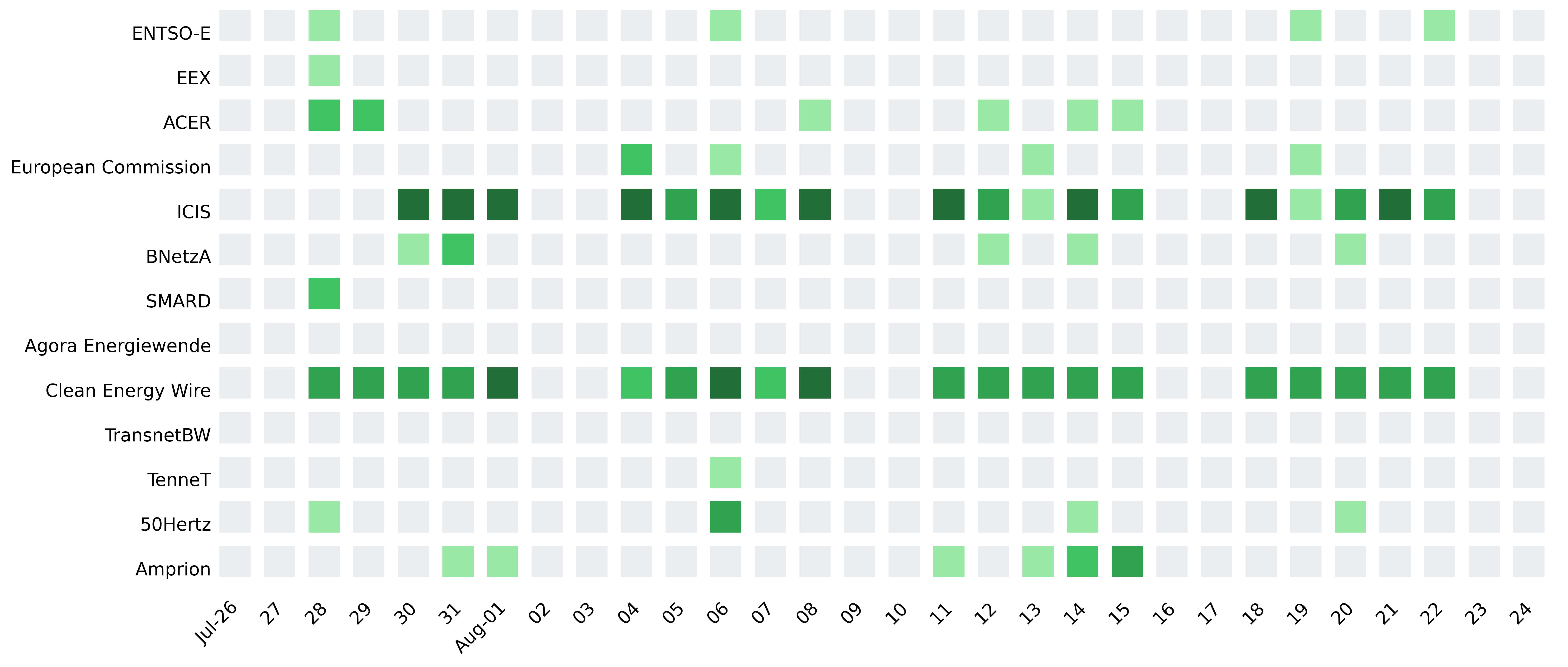
The built scraping pipeline runs once a day and appends new preprocessed posts to the source database.
Critically, the scraped posts database is located in a private repository, ensuring compliance with copyright and data protection regulations.
3. Temporally-Aware Knowledge Graphs: The Architectural Choice
Extracting coherent information from fragmented sources is a common challenge across industries. In finance, pipelines merge structured filings (e.g., XBRL-tagged 10-K/10-Qs) with semi-structured earnings-call transcripts, aligning entities, normalizing revisions, and time-stamping events so analysts can track "what changed between quarters." In manufacturing, companies use industrial knowledge graphs and standards like the Asset Administration Shell (AAS) to link manuals, parts catalogs, and life-cycle data, allowing teams to answer questions such as "which component version was installed when?"
For this project, I decided to proceed with Temporal Knowledge Graphs (TKGs), graphs in which entities and relations include validity intervals or timestamps.
Understanding Temporal Knowledge Graphs
The OpenAI Cookbook’s approach to Temporally-aware Knowledge Graphs represents a compelling solution to the challenge of modeling evolving information landscapes. It illustrates how a TKG can be built from a collection of companies' earnings calls, starting from chunking the raw data (text transcripts) into semantic blocks and finishing with multi-step retrieval agents.
A TKG consists of:
Entities: E.g., organizations (TSOs, regulators), infrastructure (power plants, transmission lines), concepts (regulations, market mechanisms)
Relationships: Temporal edges connecting entities with validity periods and evolution patterns
Events: Discrete occurrences that trigger state changes or relationship modifications
Temporal Metadata: Timestamps, durations, and temporal qualifiers for all graph elements
The choice of TKG is motivated by the energy sector's characteristics that make it particularly amenable to TKG representation:
Temporal Dependencies: Energy markets exhibit strong temporal patterns-seasonal demand, project timelines, regulatory phase-ins-that static models cannot capture effectively.
Cross-Reference Complexity: Sources frequently reference past events, ongoing projects, and future projections within single articles. TKGs naturally handle these multi-temporal references.
Evolution Tracking: Regulatory frameworks, market structures, and infrastructure evolve continuously. TKGs maintain historical states while representing current reality.
Causal Reasoning: Understanding energy markets requires tracing cause-and-effect chains across time, from policy announcements to implementation to market response.
Heterogeneous Update Frequencies: Different sources publish at varying cadences (daily market data vs. quarterly regulatory updates). TKGs accommodate this temporal heterogeneity naturally.
In summary, unlike static graphs, TKGs support "as-of," "change-since," and "sequence-aware" queries, making them ideal for evolving domains. Advances in LLMs further strengthen this approach by enabling automatic extraction of time-anchored triples - structured statements of the form (subject - predicate - object), such as (Germany, has_installed_capacity, 120GW_Renewables) - extended with time validity to capture when facts hold.
4. Semantic Chunking: The Foundation Layer
The Role of Chunking in Knowledge Graph Construction
Before extracting entities and relationships for the knowledge graph, raw text must be segmented into semantically coherent units. This chunking step is important since it preserves context when articles discuss multiple topics, ensuring each unit remains topically coherent and improving entity extraction accuracy. It also maintains temporal scope by keeping events and statements tied to their specific time periods, something that could be lost in sentence-level processing. Chunking further enhances computational efficiency by reducing the size of text segments, easing LLM context requirements and enabling parallel processing. Finally, it clarifies relationships between entities, which are more accurately identified within cohesive chunks than across entire documents.
Implementation Details
The chunking implementation (`chunking.py` in the repo) follows the OpenAI Cookbook closely, utilizing the Chonkie library's `SemanticChunker` with OpenAI embeddings. Key design decisions include:
Embedding Model: Using `text-embedding-3-small` balances quality with cost (approximately $0.00001 per 1,000 tokens)
Similarity Threshold: Set at 0.7 to balance granularity with coherence (see justification in preliminary results below)
Minimum Sentences: Requiring at least 2 sentences per chunk prevents over-fragmentation
Parallel Processing: ThreadPoolExecutor enables concurrent chunk generation for multiple documents
The `Publication` class contains both document metadata (source, publication date, URL) and its semantic chunks, maintaining the connection between chunks and their source context - will be used for citation and provenance tracking in the final knowledge graph.
To evaluate the chunking pipeline's effectiveness, I analyzed 50 recent ENTSO-E posts, computing metrics that help assess the semantic chunking process's quantitative and qualitative characteristics.
Chunking Performance Metrics
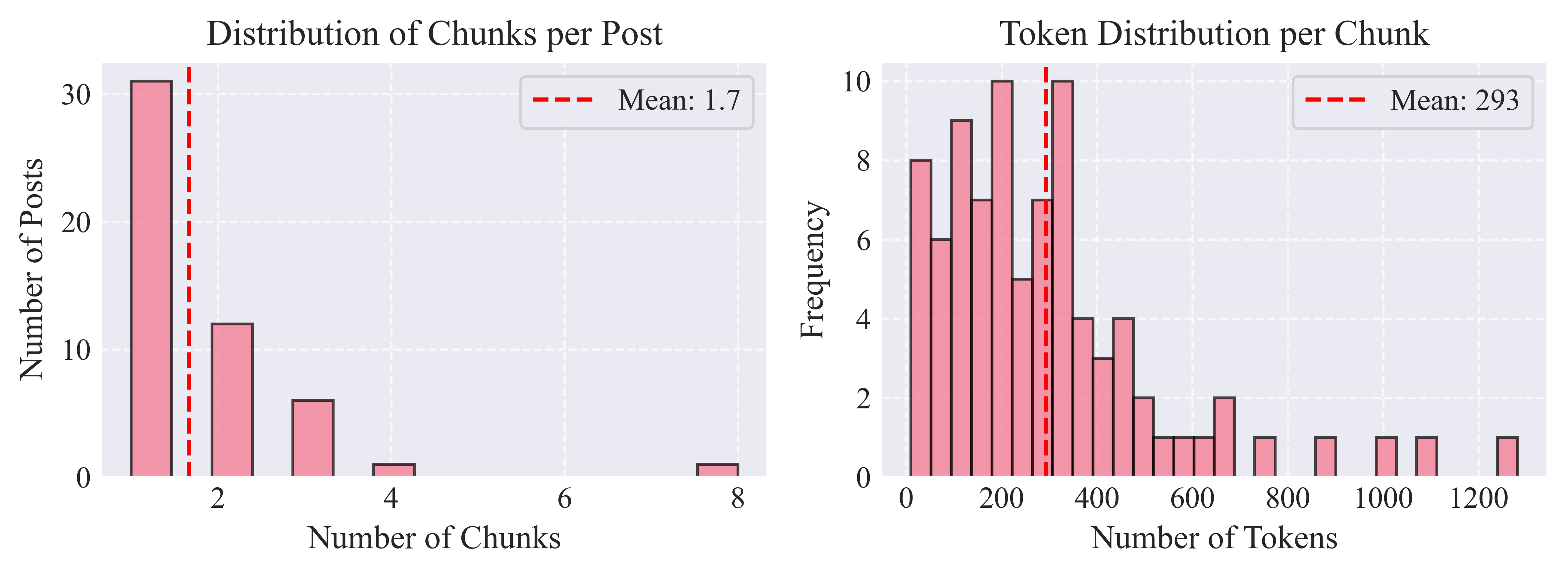
Granularity: Posts averaged 1.7 chunks (σ=1.2), indicating that ENTSO-E posts are already quite condensed in their information.
Chunk Size Distribution: Chunks averaged 293 tokens (σ=238), translating to approximately 9.1 sentences per chunk. This size should balance the context preservation with processing efficiency, i.e., large enough to maintain semantic coherence, yet small enough for efficient LLM processing.
Semantic Coherence: Using TF-IDF similarity analysis within chunks, I find mean coherence scores of 0.06.
Threshold Sensitivity Analysis
The similarity threshold parameter significantly impacts chunking behavior. My sensitivity analysis across thresholds from 0.5 to 0.9 revealed:
Low thresholds (0.5-0.6): Produce fewer, larger chunks (2-3 per post), potentially missing important topical transitions
Optimal range (0.7-0.8): Balances granularity with coherence, yielding 4-5 chunks per post
High thresholds (0.8-0.9): Over-fragment content into 7+ chunks, risking loss of contextual relationships
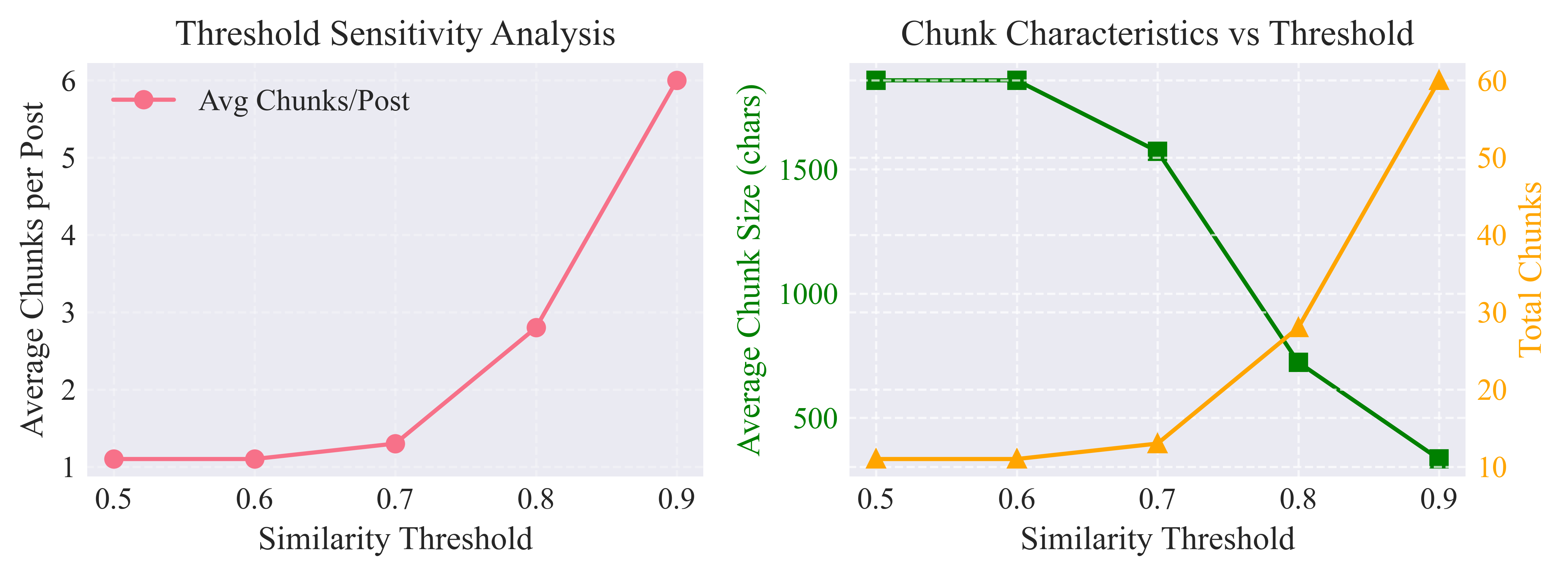
The selected threshold of 0.7 appears to be optimal, confirmed by the coherence scores and manual inspection of chunk boundaries.
Cost-Effectiveness
The embedding generation cost for processing 50 posts totaled approximately $0.012, demonstrating the economic viability of the approach. Extrapolating to the full dataset of 13 sources with hundreds of posts monthly, the total embedding cost remains under $1 per month.
5. Planned Next Stages
Now, I am continuing to build the TKG. This involves the following steps:
Entity and Relationship Extraction: Leveraging the semantic chunks to identify key entities (organizations, infrastructure, regulations) and their relationships, with temporal qualifiers extracted from contextual cues.
Graph Construction: Building the initial graph structure using extracted entities and relationships, implementing temporal versioning to track evolution.
Incremental Updates: Developing mechanisms to integrate new daily scraped content into the existing graph, detecting changes, conflicts, and emerging patterns.
Query Interface: Implementing natural language query capabilities that leverage the temporal dimension - enabling questions about trends, causality, and predictions.
Naturally, I plan to document the project development here and release all the code on GitHub.